⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、英語版を参照してください。
- サンドボックスランタイム
- クラシックランタイム
サンドボックスランタイムでは、Agent ノードは LLM に自律的なコマンドライン実行能力を与えます。ツールの呼び出し、スクリプトの実行、内部ファイルシステムや外部リソースへのアクセス、マルチモーダル出力の生成が可能です。これにはトレードオフがあります:レスポンス時間が長くなり、トークン消費も増えます。シンプルなタスクをより速く効率的に処理するには、Agent モード をオフにしてこれらの機能を無効にできます。どこから始めればよいかわからない場合や、既存のプロンプトを改善したい場合は、AI アシスト付きプロンプトジェネレーターをお試しください。
デフォルトでは、すべての可能な指示をモデルに送信し、条件を説明し、どれに従うかをモデルに判断させる必要がありますが、この方法は必ずしも信頼できるとは限りません。Jinja2 テンプレートを使えば、定義された条件に合致する指示のみが送信されるため、動作が予測可能になり、トークンの使用量も削減されます。メモリを有効にすると最近の対話が保持され、LLM がフォローアップの質問に一貫して回答できるようになります。現在のユーザークエリとアップロードされたファイルを渡すためのユーザーメッセージが自動的に追加されます。これはメモリが最近のユーザー-アシスタント間のやり取りを保存することで機能するためです。ユーザークエリがユーザーメッセージを通じて渡されないと、ユーザー側で記録するものがなくなります。ウィンドウサイズは保持する最近のやり取り数を制御します。例えば 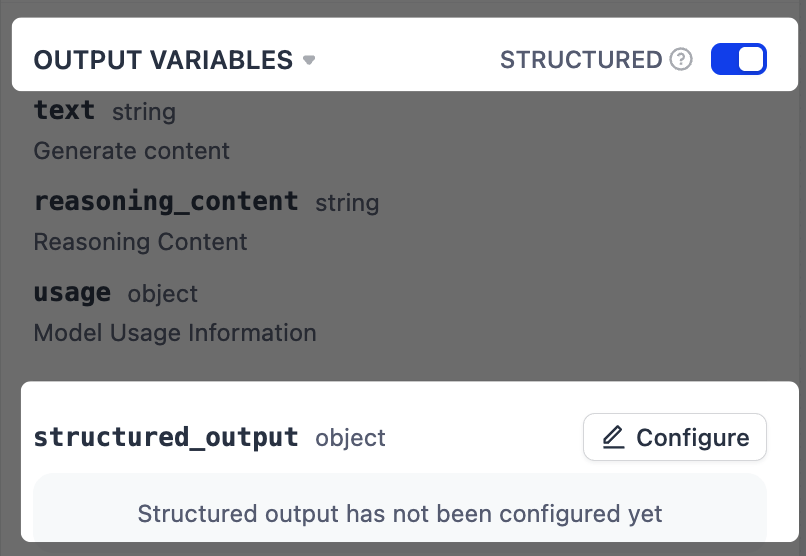

モデルの選択
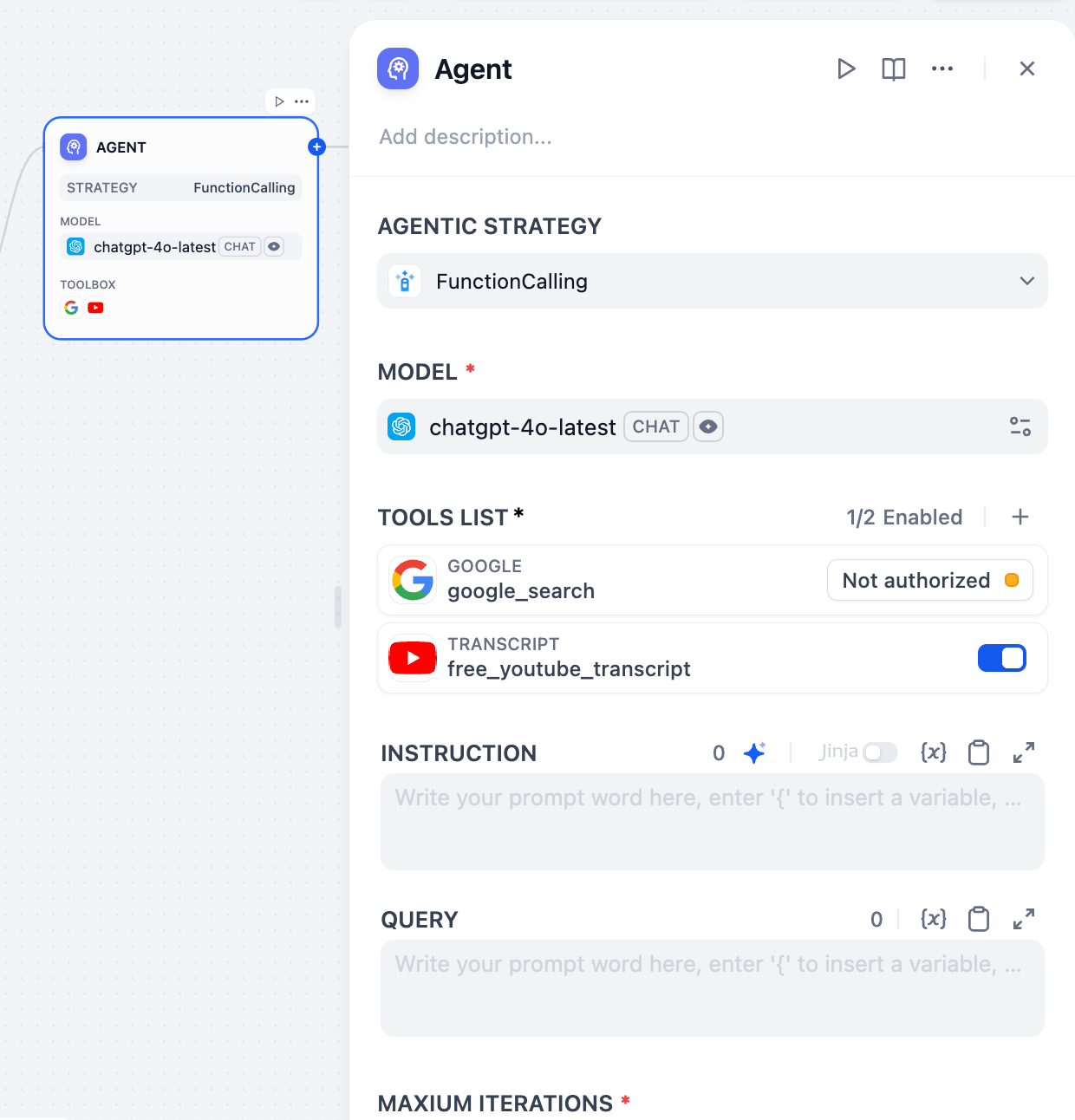
設定済みのプロバイダーからタスクに最適なモデルを選択します。選択後、モデルパラメータを調整してレスポンスの生成方法を制御できます。利用可能なパラメータとプリセットはモデルによって異なります。プロンプトの作成
モデルに入力の処理方法とレスポンスの生成方法を指示します。/ を入力して変数やファイルシステム内のリソースを挿入したり、@ を入力して Dify ツールを参照したりできます。必要なリソースがファイルシステムにまだ存在しない場合、Add files をクリックしてファイルを直接作成またはアップロードできます。デフォルトの work はルートディレクトリです。新しいファイルを作成する際、拡張子付きのファイル名を入力できます(例: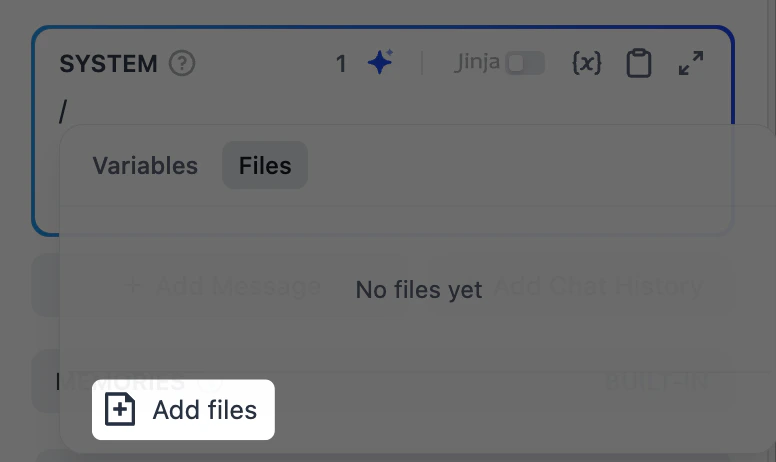
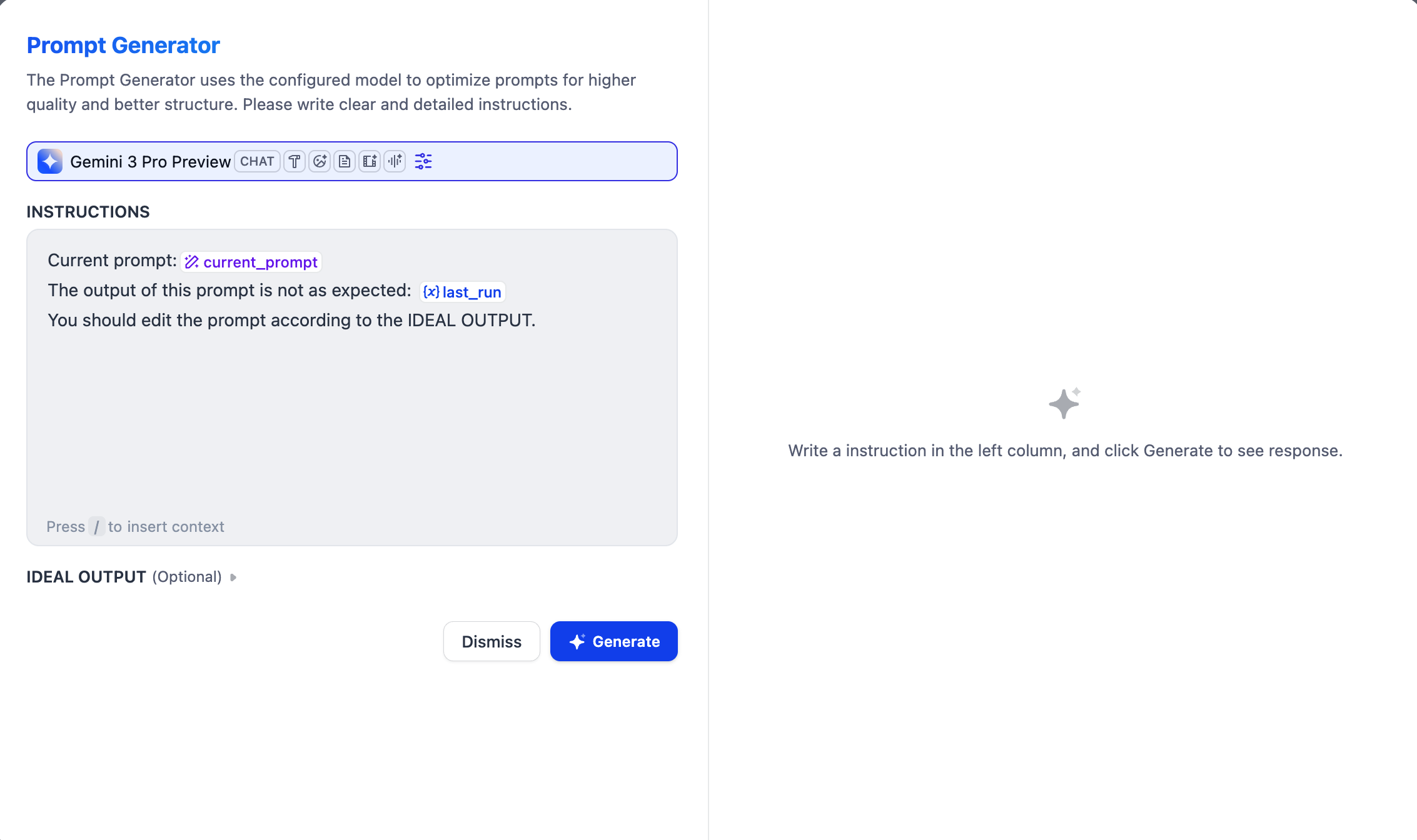
report.md)。ファイルは空の状態で作成されます——先にプロンプトで参照し、後からファイルシステムで内容を追加できます。プロンプトジェネレーターアイコン
プロンプトジェネレーターインターフェース
指示とメッセージの指定
システム指示を定義し、メッセージを追加をクリックしてユーザー/アシスタントメッセージを追加します。すべて順番にプロンプトとしてモデルに送信されます。モデルと直接会話するイメージです:- システム指示はモデルのレスポンスルールを設定します——役割、トーン、行動ガイドライン。
- ユーザーメッセージはモデルに送信する内容——質問、リクエスト、タスク。
- アシスタントメッセージはモデルのレスポンスです。
入力とルールの分離
システム指示で役割とルールを定義し、ユーザーメッセージで実際のタスク入力を渡します。例:対話履歴のシミュレーション
アシスタントメッセージがモデルのレスポンスなら、なぜ手動で追加するのか疑問に思うかもしれません。ユーザーメッセージとアシスタントメッセージを交互に追加することで、プロンプト内に対話履歴をシミュレーションできます。モデルはこれらを過去のやり取りとして扱い、動作の誘導に役立ちます。上流 LLM からの対話履歴のインポート
対話履歴の追加をクリックして、上流の Agent ノードから対話履歴をインポートします。これによりモデルは上流で何が起こったかを把握し、そのノードが中断したところから続けることができます。対話履歴にはユーザーメッセージ、アシスタントメッセージ、が含まれます。Agent ノードのcontext 出力変数で確認できます。システム指示はノード固有のため含まれません。
- 対話履歴をインポートしない場合、下流ノードは上流ノードの最終出力のみを受け取り、それがどのように導き出されたかはわかりません。
- 対話履歴をインポートすると、プロセス全体が見えます:ユーザーが何を質問したか、どのツールが呼び出されたか、どのような結果が返されたか、モデルがどのように推論したか。
例:上流 LLM が生成したファイルの処理
例:上流 LLM が生成したファイルの処理
2つの Agent ノードが順番に実行されるとします:Agent A はデータを分析してチャート画像を生成し、サンドボックスの出力フォルダーに保存します。Agent B はこれらのチャートを含む最終レポートを作成します。Agent B が Agent A の最終テキスト出力のみを受け取る場合、分析結論はわかりますが、どのファイルが生成されどこに保存されているかはわかりません。Agent A の対話履歴をインポートすることで、Agent B はツールメッセージから正確なファイルパスを確認でき、チャートをレポートに埋め込むことができます。Agent A の対話履歴インポート後に Agent B が受け取る完全なメッセージシーケンス:Agent A の対話履歴をインポートすることで、Agent B はどのファイルが存在し、どこにあるかを正確に把握し、レポートに直接埋め込むことができます。
Jinja2 を使った動的プロンプトの作成
Jinja2 テンプレートを使って、プロンプトに条件分岐、ループ、その他のロジックを追加できます。例えば、変数の値に応じて指示をカスタマイズできます。例:ユーザーレベルに応じた条件付きシステム指示
例:ユーザーレベルに応じた条件付きシステム指示
コマンド実行の有効化(Agent モード)
Agent モードをオンにすると、モデルが組み込みの bash ツールを使ってサンドボックスランタイムでコマンドラインを実行できるようになります。これはすべての高度な機能の基盤です:モデルが他のツールを呼び出す、ファイル操作を行う、スクリプトを実行する、外部リソースにアクセスする——これらすべては bash ツールを呼び出して基盤となるコマンドラインを実行することで行われます。これらの機能が不要なシンプルなタスクでは、Agent モードをオフにすることで、より高速なレスポンスと低いトークンコストを実現できます。最大イテレーション回数の調整高度な設定の最大イテレーション回数は、モデルが1つのリクエストに対して推論-行動サイクル(思考、ツール呼び出し、結果処理)を繰り返す回数を制限します。複数のツール呼び出しを必要とする複雑なマルチステップタスクでは、この値を増やしてください。値が大きいほどレイテンシとトークンコストが増加します。対話メモリの有効化(チャットフローのみ)
メモリはこのノード内でのみ有効です。異なる会話間では保持されません。
5 は、直近の5組のユーザークエリと LLM レスポンスを保持します。コンテキストの追加
高度な設定 > コンテキストで、LLM に追加の参照情報を提供し、ハルシネーションを減らしてレスポンスの精度を向上させます。一般的なパターン:ナレッジ検索ノードから検索結果を渡すことで、検索拡張生成(RAG)を実現します。マルチモーダル入力の処理
マルチモーダル対応モデルに画像、音声、動画、ドキュメントを処理させるには、以下のいずれかの方法を選択します:- プロンプトでファイル変数を直接参照する。
-
高度な設定で Vision を有効にし、ファイル変数を選択する。
解像度は画像処理の詳細レベルのみを制御します:
- 高:複雑な画像でより高精度だが、より多くのトークンを使用
- 低:シンプルな画像でより高速、より少ないトークンで処理
思考プロセスとツール呼び出しをレスポンスから分離
モデルの思考プロセスやツール呼び出しを含まないクリーンなレスポンスを取得するには、generations.content 出力変数を使用します。generations 変数自体にはすべての中間ステップと最終レスポンスが含まれます。下流ノードに適した出力変数の選択
-
generations— すべてが必要な場合:最終レスポンス、思考プロセス、ツール呼び出し、生成されたアーティファクト。 -
generations.content— クリーンなレスポンスのみが必要な場合。 -
files— 生成されたアーティファクトのみが必要な場合。
構造化出力の強制
指示で出力形式を記述しても、一貫性のない結果が生じることがあります。より信頼性の高いフォーマットを実現するには、構造化出力を有効にして定義済みの JSON スキーマを強制します。ネイティブ JSON をサポートしないモデルの場合、Dify はスキーマをプロンプトに含めますが、厳密な遵守は保証されません。
-
出力変数の横で構造化をオンにします。出力変数リストの末尾に
structured_output変数が表示されます。 -
設定をクリックし、以下のいずれかの方法で出力スキーマを定義します。
- ビジュアルエディター:ノーコードインターフェースでシンプルな構造を定義。対応する JSON スキーマが自動生成されます。
- JSON Schema:ネストされたオブジェクト、配列、バリデーションルールを含む複雑な構造のスキーマを直接記述。
- AI 生成:自然言語でニーズを記述し、AI にスキーマを生成させる。
- JSON インポート:既存の JSON オブジェクトを貼り付けて、対応するスキーマを自動生成。
エラー処理
一時的な問題(ネットワークの不具合など)に対する自動リトライ、またはエラーが続く場合にワークフローの実行を継続するための代替エラー処理戦略を設定します。