

⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考英文原版。
选择模型
从你已配置的提供商中选择最适合任务的模型。 选择后,你可以调整模型参数来控制其生成响应的方式。可用的参数和预设因模型而异。编写提示词
指导模型如何处理输入和生成响应。输入/ 或 { 来引用变量。
如果你不确定从哪里开始或想优化现有的提示词,可以试试我们的 AI 辅助提示词生成器。
提示词生成器图标
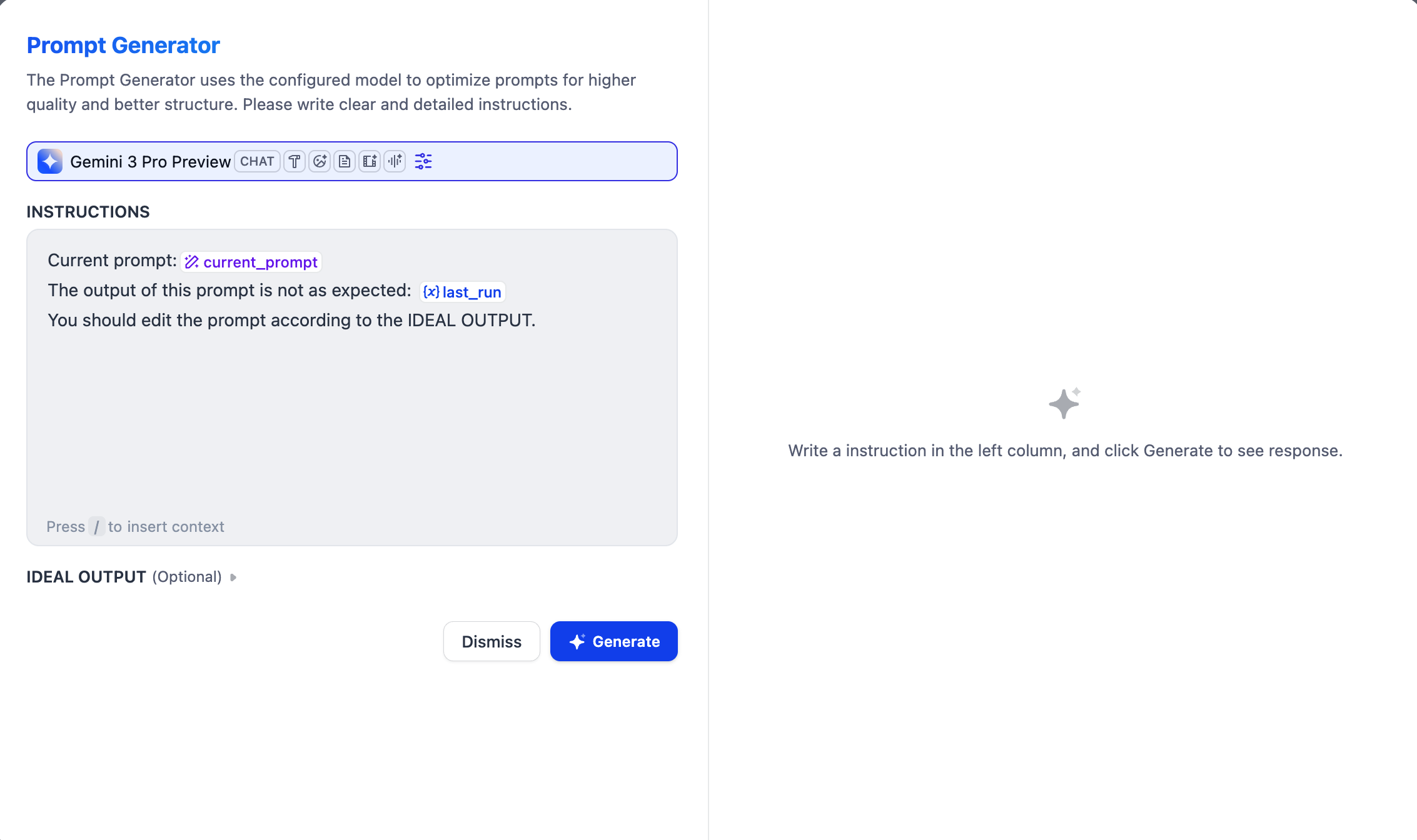
提示词生成器界面
指定指令和消息
定义系统指令并点击添加消息来添加用户/助手消息。它们会按顺序在提示词中发送给模型。 想象你正在与模型直接对话:- 系统指令设定模型响应的规则——角色、语气和行为准则。
- 用户消息是你发送给模型的内容——问题、请求或要模型完成的任务。
- 助手消息是模型的回复。
将输入与规则分离
在系统指令中定义角色和规则,然后在用户消息中传递实际的任务输入。例如:模拟对话历史
你可能会想:既然助手消息是模型的回复,为什么要手动添加它们? 通过交替添加用户和助手消息,你可以在提示词中创建模拟的对话历史。模型会将这些视为之前的对话,这有助于引导其行为。从上游 LLM 导入对话历史
点击添加对话历史,从上游 Agent 或 LLM 节点导入对话历史。这让模型了解上游发生了什么,并从其结束的地方继续。 对话历史包括用户消息、助手消息和。你可以在 Agent 或 LLM 节点的context 输出变量中查看。
系统指令不包含在内,因为它们是节点特定的。
- 不导入对话历史时,下游节点只接收上游节点的最终输出,不知道它是如何得出结论的。
- 导入对话历史后,它可以看到整个过程:用户问了什么、调用了哪些工具、返回了什么结果、模型是如何推理的。
示例:串联研究和报告 LLM
示例:串联研究和报告 LLM
假设两个 LLM 节点依次运行:LLM A 通过调用搜索工具研究一个主题,LLM B 基于研究结果撰写报告。如果 LLM B 只接收 LLM A 的最终文本输出,它可以总结结论,但可能无法验证或引用具体来源。通过导入 LLM A 的对话历史,LLM B 可以看到每次工具调用的原始数据,并在报告中直接引用。以下是 LLM B 导入 LLM A 对话历史后看到的完整消息序列:导入对话历史后,LLM B 就能理解:它已经看到了研究过程(问题、搜索、总结),现在需要基于这些信息撰写报告——包括仅通过文本输出无法获取的原始数据。
使用 Jinja2 创建动态提示词
使用 Jinja2 语法创建动态提示词。例如,使用条件判断根据变量值定制不同的指令。Jinja2 示例:根据用户级别设置条件提示词
Jinja2 示例:根据用户级别设置条件提示词
添加上下文
在高级设置 > 上下文中,为 LLM 提供额外的参考信息,以减少幻觉并提高响应准确性。 典型模式:从知识检索节点传递检索结果,实现检索增强生成(RAG)。启用对话记忆(仅对话流)
记忆是节点特定的,仅在同一个对话中生效。
5 保留最近 5 轮用户输入和 LLM 回复。
调用 Dify 工具
只有带有 Tool Call 标签的模型才能调用 Dify 工具。
处理多模态输入
要让支持多模态的模型处理图片、音频、视频或文档,可选择以下任一方式:- 在提示词中直接引用文件变量。
-
在高级设置中启用 Vision 并在那里选择文件变量。
分辨率仅控制图片处理的细节级别:
- 高:对复杂图片更准确,但消耗更多 Token
- 低:对简单图片处理更快,消耗更少 Token
将思考过程和工具调用与响应分离
若要获得不包含模型思考过程和工具调用(如果有)的干净响应,请引用text 输出变量(开启启用推理标签分离)或 generation.content。
generations 变量本身包含所有中间步骤和最终响应。
强制结构化输出
在指令中描述输出格式可能产生不一致的结果。若要实现更可靠的格式化,启用结构化输出以强制执行定义好的 JSON schema。对于不支持原生 JSON 的模型,Dify 会将 schema 包含在提示词中,但模型不一定严格遵循。
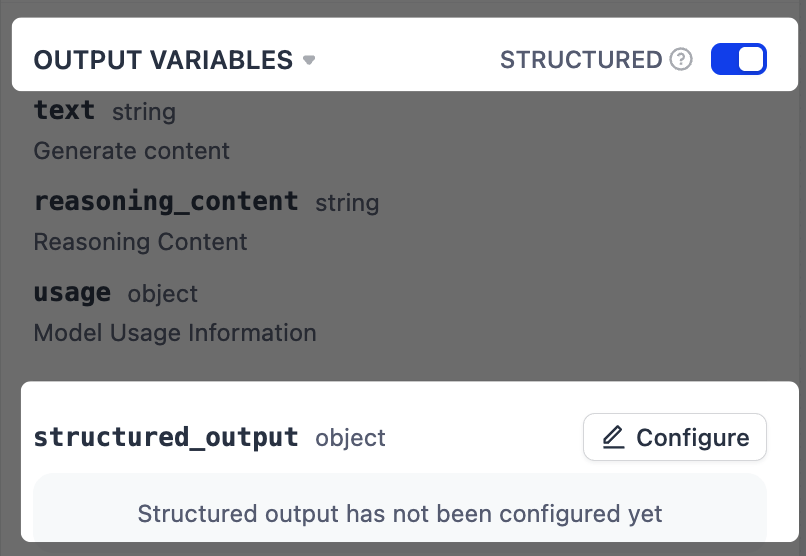
-
在输出变量旁,启用结构化开关。一个
structured_output变量将出现在输出变量列表末尾。 -
点击配置,使用以下方法之一定义输出 schema。
- 可视化编辑器:使用无代码界面定义简单结构。对应的 JSON schema 会自动生成。
- JSON Schema:直接编写 schema,适用于包含嵌套对象、数组或验证规则的复杂结构。
- AI 生成:用自然语言描述需求,让 AI 生成 schema。
- JSON 导入:粘贴一个现有的 JSON 对象,自动生成对应的 schema。
错误处理
为临时问题(如网络波动)配置自动重试,或设置备用错误处理策略以在错误持续时保持工作流运行。