⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考英文原版。
- 沙盒运行时
- 经典运行时
在沙盒运行时中,Agent 节点赋予 LLM 自主执行命令行的能力,使其可以调用工具、运行脚本、访问内部文件系统和外部资源,以及创建多模态输出。这也带来了权衡:更长的响应时间和更高的 Token 消耗。要更快更高效地处理简单任务,可以关闭 Agent 模式 来禁用这些功能。如果你不确定从哪里开始或想优化现有的提示词,可以试试我们的 AI 辅助提示词生成器。
默认情况下,你需要将所有可能的指令发送给模型,描述条件,然后让模型自行决定遵循哪些——这种方法往往不够可靠。使用 Jinja2 模板,只有符合定义条件的指令会被发送,确保行为可预测并减少 Token 使用。启用记忆以保留最近的对话,使 LLM 能够连贯地回答后续问题。一条用户消息会被自动添加来传递用户输入和任何上传的文件。这是因为记忆通过存储最近的用户-助手消息交互来工作。如果用户输入不通过用户消息传递,用户侧将没有内容可记录。窗口大小控制保留多少条最近的交互。例如,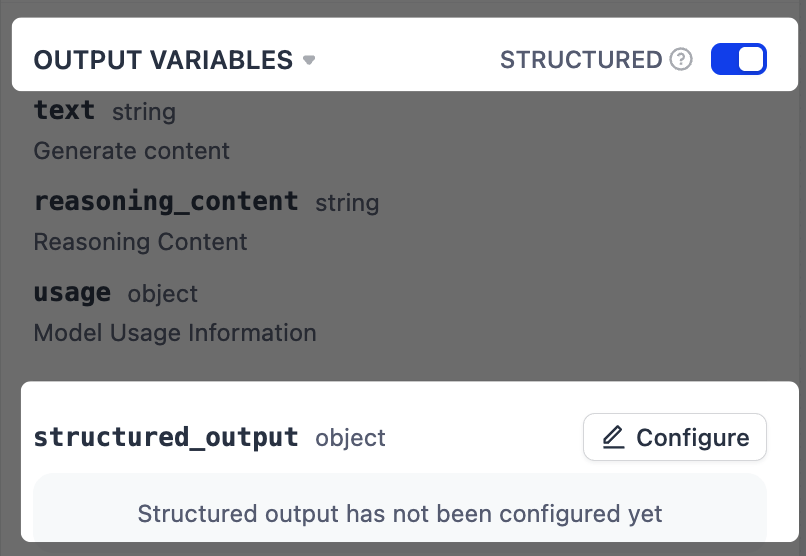

选择模型
从你已配置的提供商中选择最适合任务的模型。选择后,你可以调整模型参数来控制其生成响应的方式。可用的参数和预设因模型而异。编写提示词
指导模型如何处理输入和生成响应。输入/ 可插入变量或文件系统中的资源,输入 @ 可引用 Dify 工具。如果你需要的资源在文件系统中尚不存在,点击 添加文件 可直接创建或上传文件。默认的 work 是根目录。创建新文件时,你可以输入带扩展名的文件名(例如 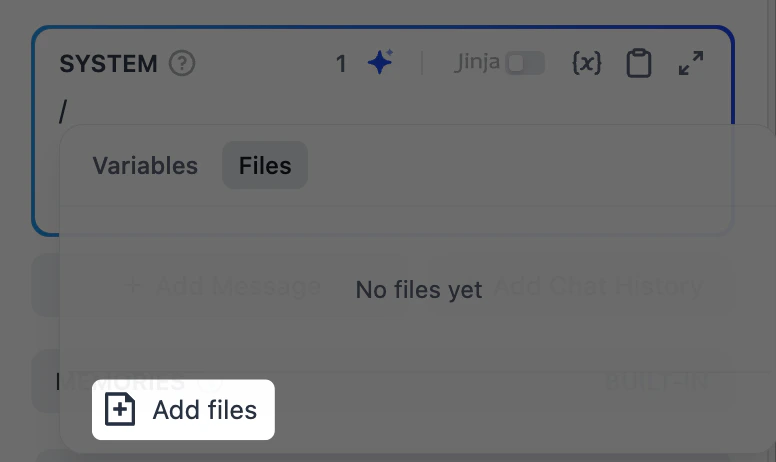
report.md)。文件创建后为空——你可以先在提示词中引用它,稍后再在文件系统中填充内容。提示词生成器图标
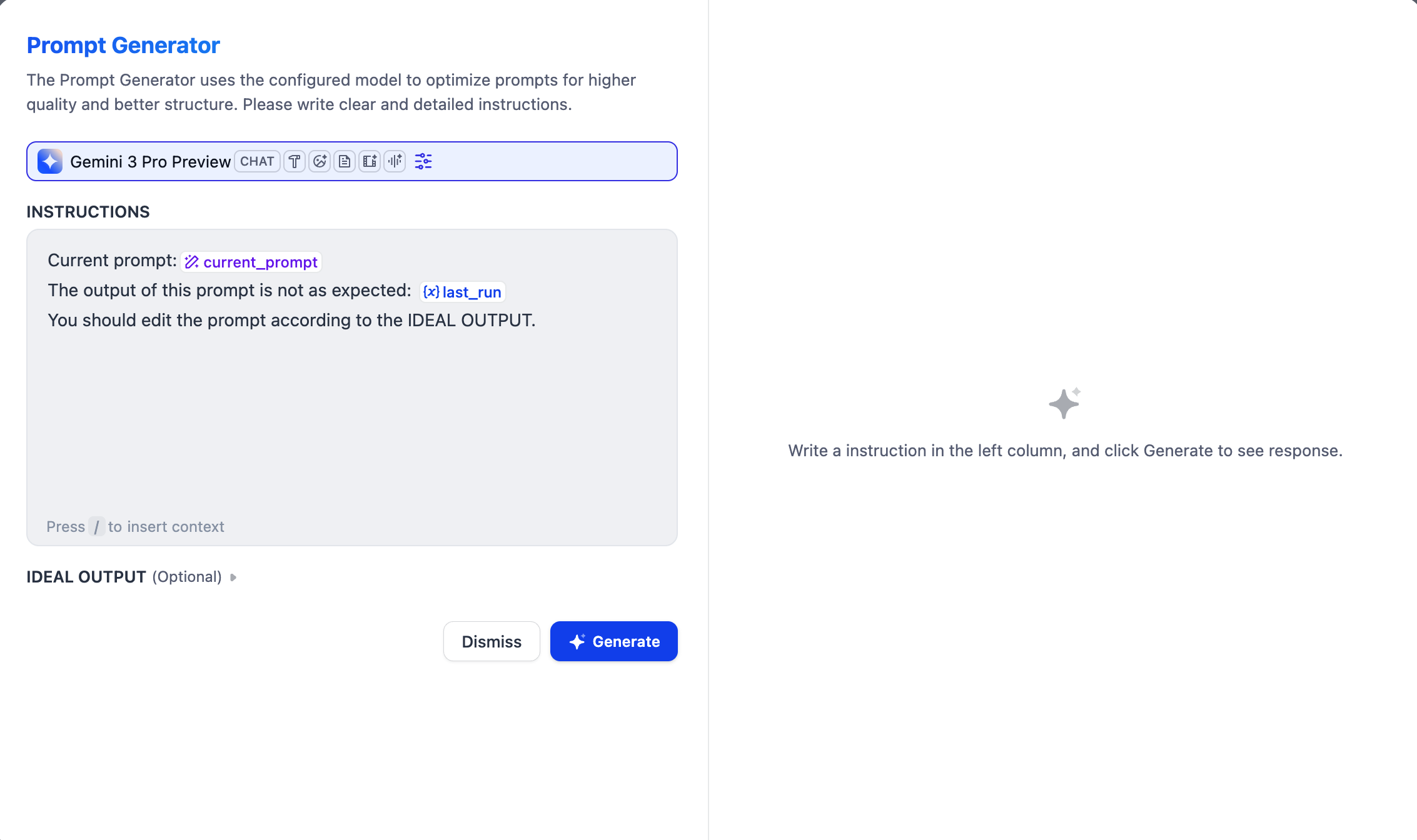
提示词生成器界面
指定指令和消息
定义系统指令并点击添加消息来添加用户/助手消息。它们会按顺序在提示词中发送给模型。想象你正在与模型直接对话:- 系统指令设定模型响应的规则——角色、语气和行为准则。
- 用户消息是你发送给模型的内容——问题、请求或要模型完成的任务。
- 助手消息是模型的回复。
将输入与规则分离
在系统指令中定义角色和规则,然后在用户消息中传递实际的任务输入。例如:模拟对话历史
你可能会想:既然助手消息是模型的回复,为什么要手动添加它们?通过交替添加用户和助手消息,你可以在提示词中创建模拟的对话历史。模型会将这些视为之前的对话,这有助于引导其行为。从上游 LLM 导入对话历史
点击添加对话历史,从上游 Agent 节点导入对话历史。这让模型了解上游发生了什么,并从其结束的地方继续。对话历史包括用户消息、助手消息和。你可以在 Agent 节点的context 输出变量中查看。系统指令不包含在内,因为它们是节点特定的。
- 不导入对话历史时,下游节点只接收上游节点的最终输出,不知道它是如何得出结论的。
- 导入对话历史后,它可以看到整个过程:用户问了什么、调用了哪些工具、返回了什么结果、模型是如何推理的。
示例:处理上游 LLM 生成的文件
示例:处理上游 LLM 生成的文件
假设两个 Agent 节点依次运行:Agent A 分析数据并生成图表图片,保存到沙盒的输出文件夹。Agent B 创建包含这些图表的最终报告。如果 Agent B 只接收 Agent A 的最终文本输出,它知道分析结论,但可能不知道生成了什么文件或文件存储在哪里。通过导入 Agent A 的对话历史,Agent B 可以从工具消息中看到确切的文件路径,从而可以在报告中访问和嵌入这些图表。以下是 Agent B 导入 Agent A 对话历史后看到的完整消息序列:通过导入 Agent A 的对话历史,Agent B 可以确切地知道哪些文件存在以及它们的位置,因此可以直接将它们嵌入报告。
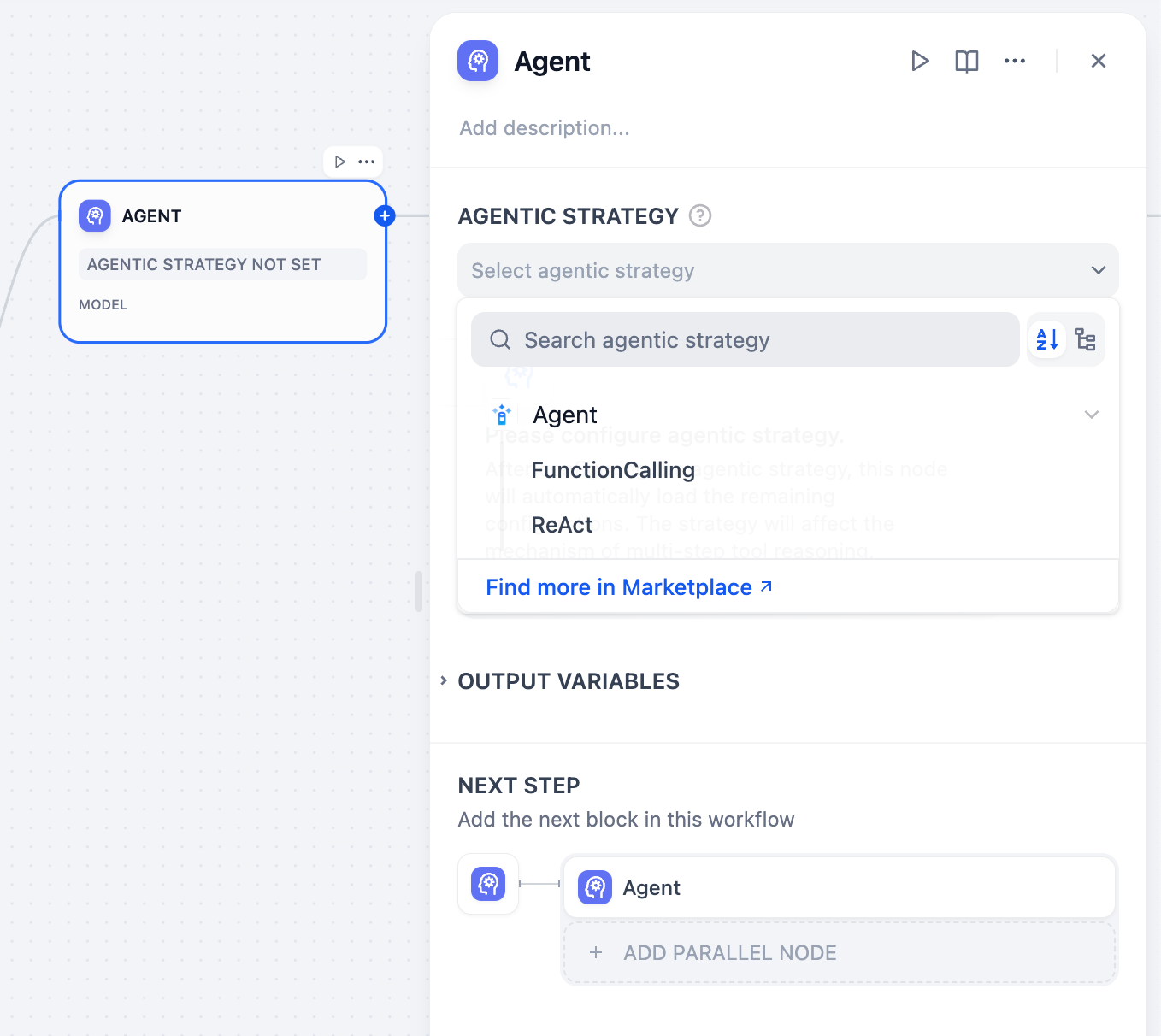
使用 Jinja2 创建动态提示词
使用 Jinja2 模板在提示词中添加条件、循环和其他逻辑。例如,根据变量值定制不同的指令。示例:根据用户级别设置条件系统指令
示例:根据用户级别设置条件系统指令
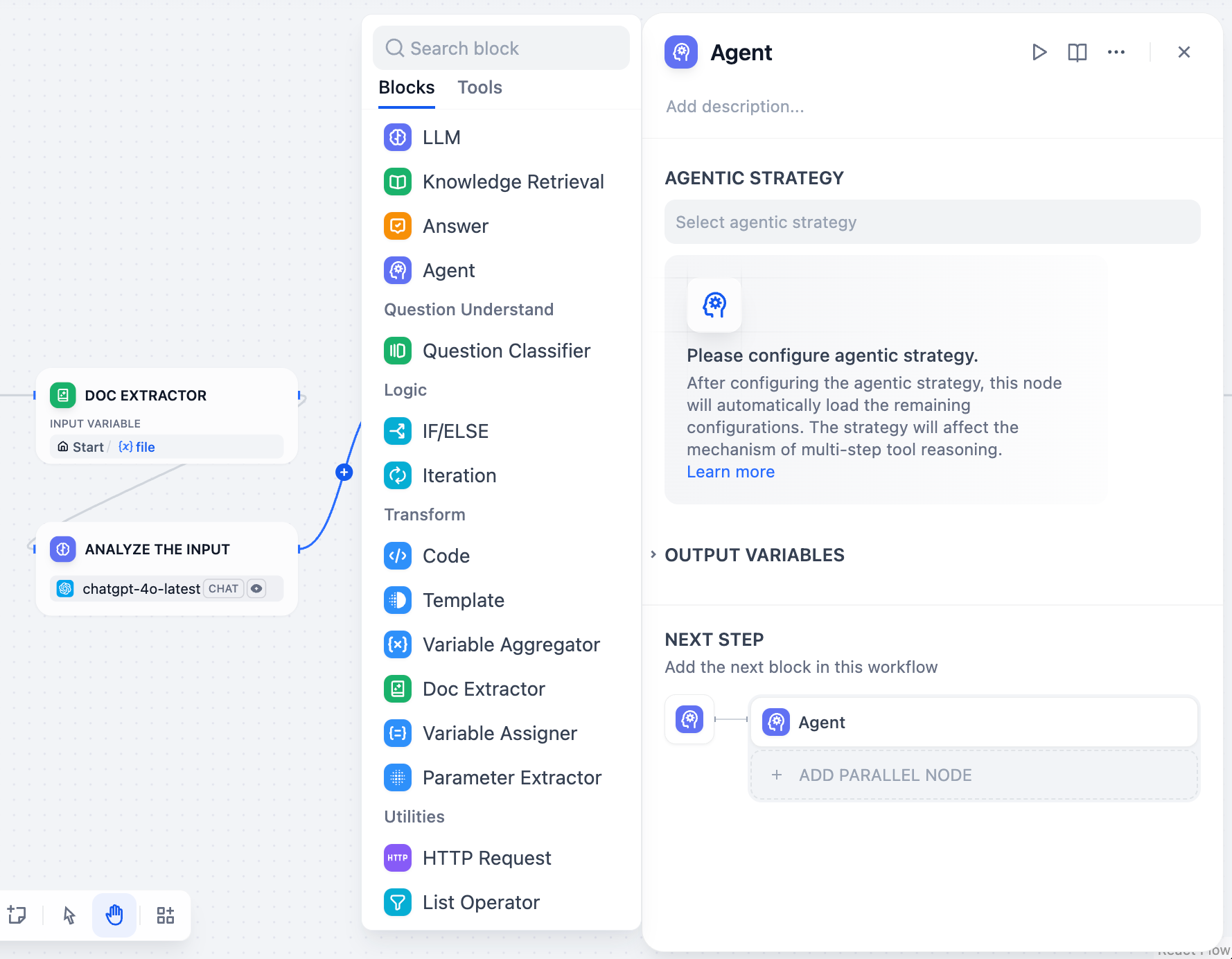
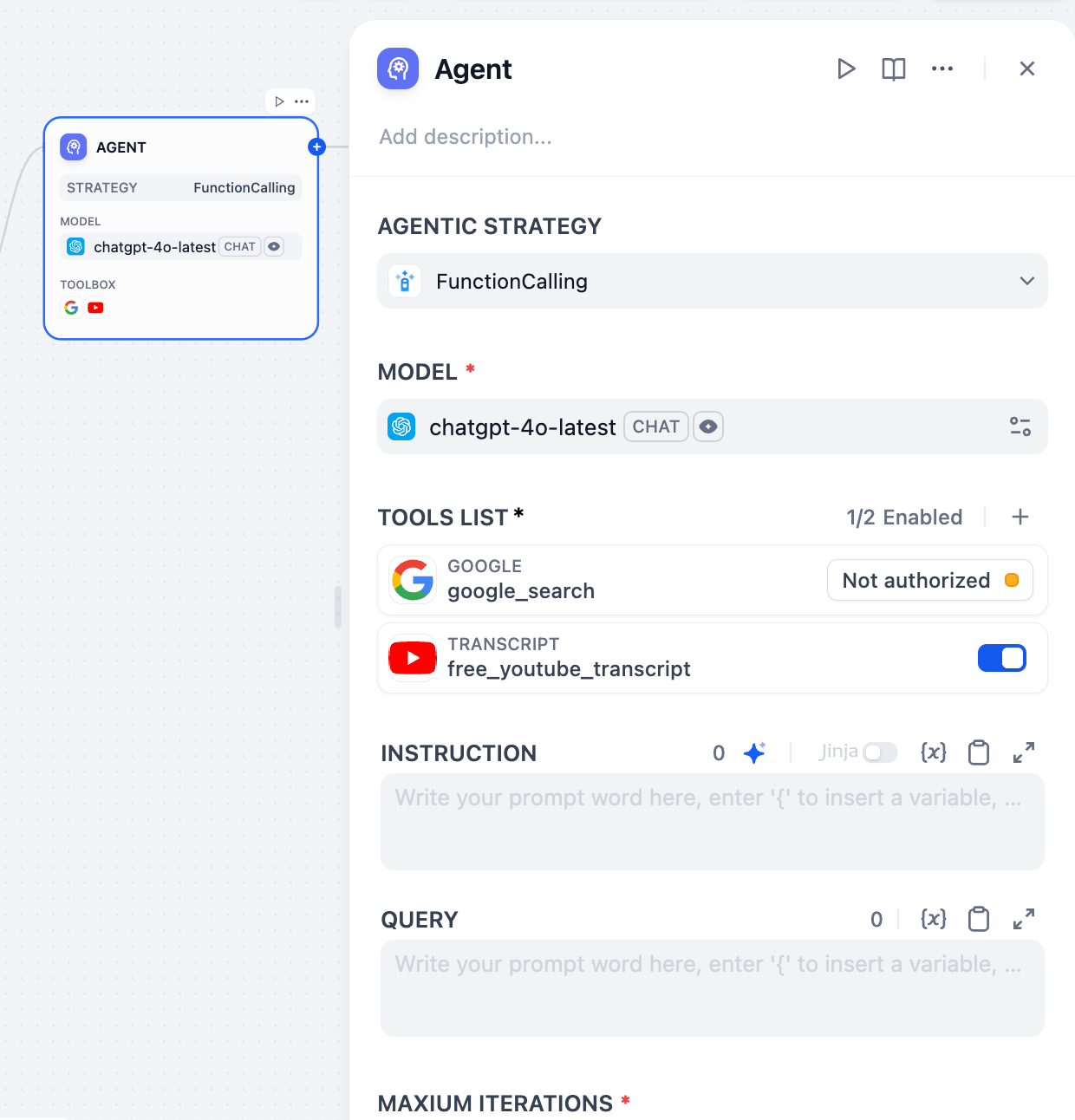
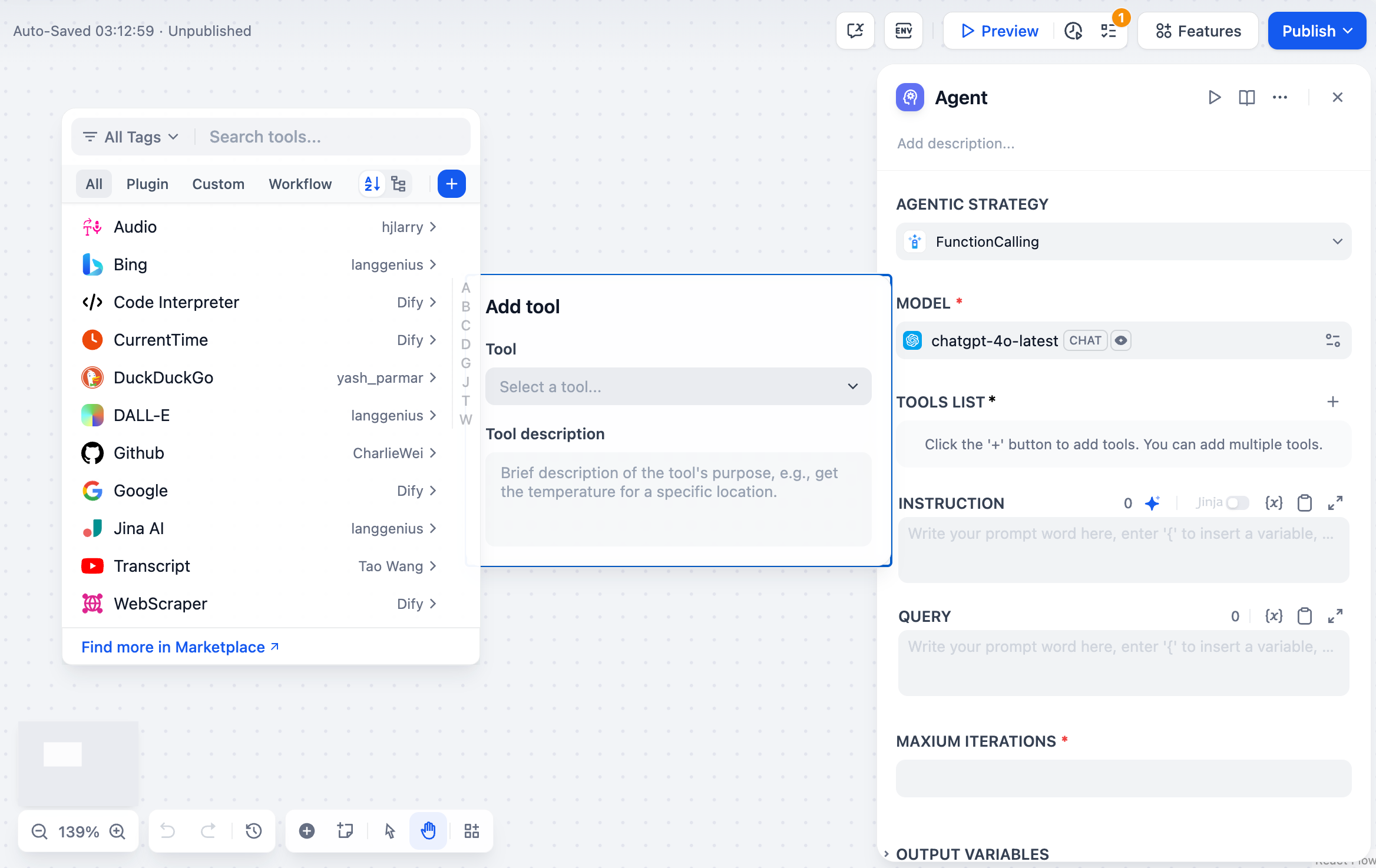
启用命令执行(Agent 模式)
开启 Agent 模式,让模型使用内置的 bash 工具在沙盒运行时中执行命令行。这是所有高级功能的基础:当模型调用其他任何工具、执行文件操作、运行脚本或访问外部资源时,它都是通过调用 bash 工具来执行底层的命令行。对于不需要这些功能的简单快速任务,可以关闭 Agent 模式 以获得更快的响应和更低的 Token 消耗。调整最大迭代次数高级设置中的最大迭代次数限制了模型对单次请求可以重复其推理-行动循环(思考、调用工具、处理结果)的次数。对于需要多次工具调用的复杂多步任务,增加此值。较高的值会增加延迟和 Token 消耗。启用对话记忆(仅对话流)
记忆是节点特定的,仅在同一个对话中生效。
5 保留最近 5 轮用户输入和 LLM 回复。添加上下文
在高级设置 > 上下文中,为 LLM 提供额外的参考信息,以减少幻觉并提高响应准确性。典型模式:从知识检索节点传递检索结果,实现检索增强生成(RAG)。处理多模态输入
要让支持多模态的模型处理图片、音频、视频或文档,可选择以下任一方式:- 在提示词中直接引用文件变量。
-
在高级设置中启用 Vision 并在那里选择文件变量。
分辨率仅控制图片处理的细节级别:
- 高:对复杂图片更准确,但消耗更多 Token
- 低:对简单图片处理更快,消耗更少 Token
将思考过程和工具调用与回复分离
若要获得不包含模型思考过程和工具调用的干净回复,请引用generations.content 输出变量。generations 变量本身包含所有中间步骤和最终回复。为下游节点选择合适的输出变量
-
generations— 需要所有内容时使用:最终回复、思考过程、工具调用以及生成的产物。 -
generations.content— 仅需要干净的回复时使用。 -
files— 仅需要生成的产物时使用。
强制结构化输出
在指令中描述输出格式可能产生不一致的结果。若要实现更可靠的格式化,启用结构化输出以强制执行定义好的 JSON schema。对于不支持原生 JSON 的模型,Dify 会将 schema 包含在提示词中,但模型不一定严格遵循。
-
在输出变量旁,启用结构化开关。一个
structured_output变量将出现在输出变量列表末尾。 -
点击配置,使用以下方法之一定义输出 schema。
- 可视化编辑器:使用无代码界面定义简单结构。对应的 JSON schema 会自动生成。
- JSON Schema:直接编写 schema,适用于包含嵌套对象、数组或验证规则的复杂结构。
- AI 生成:用自然语言描述需求,让 AI 生成 schema。
- JSON 导入:粘贴一个现有的 JSON 对象,自动生成对应的 schema。
错误处理
为临时问题(如网络波动)配置自动重试,或设置备用错误处理策略以在错误持续时保持工作流运行。